tf_物品识别后端搭建
本项目环境:
- 系统:Ubuntu 18.04-server (华为云)
- python 3.6.9
项目开始
- 这个选做:Ubuntu 换源
vim /etc/apt/sources.list # 复制下面到sources.list # 阿里源deb http://mirrors.aliyun.com/ubuntu/ bionic main restricted universe multiversedeb http://mirrors.aliyun.com/ubuntu/ bionic-security main restricted universe multiversedeb http://mirrors.aliyun.com/ubuntu/ bionic-updates main restricted universe multiversedeb http://mirrors.aliyun.com/ubuntu/ bionic-proposed main restricted universe multiversedeb http://mirrors.aliyun.com/ubuntu/ bionic-backports main restricted universe multiversedeb-src http://mirrors.aliyun.com/ubuntu/ bionic main restricted universe multiversedeb-src http://mirrors.aliyun.com/ubuntu/ bionic-security main restricted universe multiversedeb-src http://mirrors.aliyun.com/ubuntu/ bionic-updates main restricted universe multiversedeb-src http://mirrors.aliyun.com/ubuntu/ bionic-proposed main restricted universe multiversedeb-src http://mirrors.aliyun.com/ubuntu/ bionic-backports main restricted universe multiverse- 更新Ubuntu软件
# 换不换源都执行这个sudo apt-get updatesudo apt-get upgrade- 安装docker
xxxxxxxxxxcurl -fsSL https://get.docker.com -o get-docker.shsudo sh get-docker.sh- docker 镜像加速(选做)
xxxxxxxxxxsudo mkdir -p /etc/dockersudo tee /etc/docker/daemon.json <<-'EOF'{ "registry-mirrors": ["https://docker.mirrors.ustc.edu.cn/"]}EOFsudo systemctl daemon-reloadsudo systemctl restart docker菜鸟教程,这里有其他镜像地址
- 将tf_end项目复制到Ubuntu系统内,路径自己选
- 安装Dockerfile
x
# 进入到tf_end/dockerfile文件夹内(取决你的路径)# tf_py 自己定义的docker容器名称docker build -t tf_py .

- 安装Java容器
docker pull openjdk:8u342-slim- 安装redis容器
xxxxxxxxxxdocker pull redis- 6.1 一般python3库里面没有redis,顺便安装了
# 一开头已经说明我用的是python3,所以使用pip3 (针对Linux下的,其他方法安装的python看你的具体方法)# 如果pip3 没有安装(即运行下一条命令不能正常运行就是缺失pip3)sudo apt-get install python3-pip# 主机没安装py redispip3 install redis- sh脚本直接启动对应的服务
x
# 先给执行文件权限,也是执行一次就行,以后都不用chmod 777 close.sh start.sh# 打开mainpy/default.json这个修改:CONCMD# 示例:"CONCMD": "/usr/bin/python3 /home/wwl/tf_end/mainpy/client_socket.py ",/usr/bin/python3 #打开终端输入命令 which python3 获得/home/wwl/tf_end/mainpy/client_socket.py #你的文件路径# 创建一个docker网络,不写shell启动脚本里面是因为我太菜了,不能指定只执行一次,自己手动执行一次就行了,已经创建过就不用执行了docker network create tfnet# 启动服务# 进入到start.sh当前目录下,执行./start.sh- 关闭所有服务
# 进入到close.sh目录下,执行./close.sh注:特别注意两个default.json,最好不要乱改,特别是顺序,我写的start.sh启动脚本需要读取json的数据的,因为shell脚本没有直接读取json,我是靠自带的一些命令加正则得到数据的,所以乱改顺序是非常可能出错的,但修改值应该问题不大
模型
模型太大不可能直接上传到这里,自己训练。
训练完的模型需要放在model文件夹内,修改container/default.json的model,修改为你的文件名。
训练完需要更改两个default,container/default.json,mainpy/default.json
container/default.json中的indices字段,
mainpy/default.json中的names字段。
我这里给个训练模型直接得到indices的例子。names是把那个值变成中文而已。
例子:
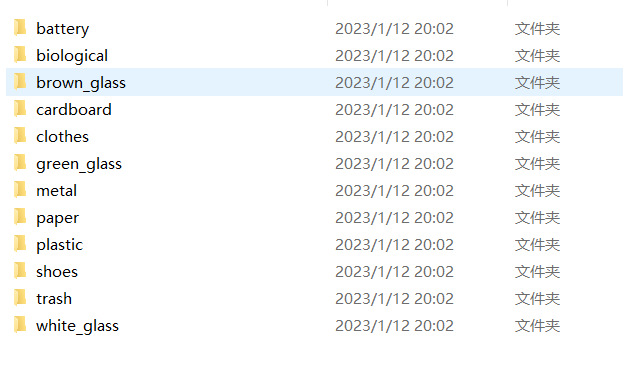
xxxxxxxxxx# 过拟合了,先试试数据增强from tensorflow.keras.preprocessing.image import ImageDataGeneratortrain_datagen = ImageDataGenerator(rescale=1./255,rotation_range=40,width_shift_range=0.2,height_shift_range=0.2,shear_range=0.2,zoom_range=0.2,horizontal_flip=True)test_datagen = ImageDataGenerator(rescale=1./255)train_generator = train_datagen.flow_from_directory(traindir,target_size=(150, 150),batch_size=20,class_mode='categorical')print(train_generator.class_indices)# 结果:{'battery': 0, 'biological': 1, 'brown_glass': 2, 'cardboard': 3, 'clothes': 4, 'green_glass': 5, 'metal': 6, 'paper': 7, 'plastic': 8, 'shoes': 9, 'trash': 10, 'white_glass': 11}# flow_from_directory这样的代码直接能得到indices代码需要的train,test,val文件夹内的文件目录
详解两个default.json
container/default.json
顾名思义,是容器内使用的配置文件,内容如下:
xxxxxxxxxx{"indices": {"battery": 0,"biological": 1,"brown_glass": 2,"cardboard": 3,"clothes": 4,"green_glass": 5,"metal": 6,"paper": 7,"plastic": 8,"shoes": 9,"trash": 10,"white_glass": 11},"path": "model","model": "Goods_categorical_6_VGG16.h5","temp_img_dir": "timgsrc"}indices的内容上面讲过。
path就是存放model文件的文件夹,相对路径的。
model就是model训练的文件名。
temp_img_dir就是临时存放上传图片的路径,也是相对路径。
注意:这里相对路径是相对于容器内的,不是当前的,当前的文件夹会挂载在容器内的/tf路径下的,所以是相对于tf文件夹内的
mainpy/default.json
主程序运行时需要的配置信息。内容如下:
xxxxxxxxxx{"temp_image_dir": "timgsrc","credisbypyfun": {"CONCMD": "/usr/bin/python3 /home/wwl/tf_end/mainpy/client_socket.py "},"pyandjvtoconbyskSer": {"addr": "localhost","port": 8002,"listen": 10,"retimes": 4},"server-socket": {"addr": "localhost","port": 8001,"listen": 10},"tf_pool": {"ALL_SER": 3,"docker_prefix": "tf_"},"names": {"battery": "电池","biological": "微生物","brown_glass": "棕色玻璃","cardboard": "硬纸箱","clothes": "衣服","green_glass": "绿色玻璃","metal": "金属","paper": "纸","plastic": "塑料","shoes": "鞋子","trash": "垃圾","white_glass": "白色玻璃"}}temp_image_dir:和container/default.json 里面的意思是一样,所以两个必须相同。为什么会有两个?是因为,一个是容器的配置,一个是主程序的配置,其实可以是同一个文件就行了,当时写的时候是按程序来分了,其实和成一个会好一点。
credisbypyfun:前面搭建的时候提到,要修改这个,因为每个人的环境和路径不一样。这个是主程序执行必要的一个参数,其实不用start.sh启动脚本的话这个不用这样写,但shell启动脚本会导致找不到python3路径和不是当前运行环境的相对路径,就导致这里需要特别精确,注意后面还有空格的就相当于执行python程序时的命令,python3 main.py 参数,这个是公共命令,后面会接不同参数的所以需要空格(可以多个,但不能没有)
pyandjvtoconbyskSer:是连接python和Java的一个socket服务,本项目采用socket通信机制连接两种语言,是相对于以前的创新。子字段addr,一般就localhost不用改。原因是本py是在主机内执行的,与其连接的是JavaWeb服务,Java的docker容器我启动时用的是主机模式的网络,所以它们同属于主机网络中,localhost就能将其连接。port端口,socket服务启动需要监听的端口,如果端口冲突可以更换。listen能同时连接的客户端的个数。retimes:重试次数,这个是为了解决并行可能导致获取同一资源获取出错,内部定义了一个锁,所以前端请求一次创建,锁上了,失败了,但不代表下次就会继续锁,为缓解前端重复请求压力,所以内部采用多次重试缓解一下。
server-socket:也是一个socket服务,该服务为了创建一个redis永久服务,将连接redis数据库次数减少到只要启动服务的时候连接一次。这样就能通过客户端连接socket服务端请求对应的函数执行redis数据库操作。也是以前的一次创新,以前直接搭建一个web服务,其实差不多,但感觉socket耗费更少一点。addr、port、listen和上面解释一样。
tf_pool:利用池化思想,将物品识别的docker容器创建几个,然后轮流使用,不用使用一次创建一次再销毁,那样时间成本高。ALL_SER是创建多少个docker容器。docker_prefix容器名的前缀,容器名称就是前缀加数字。
names:上面讲过,不多说了。
总结
socket应用更加灵活。特别是通信的时候为了能判断数据是否接收完毕,采用识别后缀的方式。为了减少原数据出现后缀的情况,我直接先用base64将数据编码,base64编码里面没有#号,所以采用#识别数据接收完毕。第一次使用socket是在上一次的项目——音乐聊天室。这次再次使用,而且更加深入了解。
此次的项目,吸取了上次科大校园小程序的教训,和学习springboot项目时发现配置文件的好处。结合两者发现,要想创建一个傻瓜式部署的项目而且可移植性强的,一定得配合配置文件使用。所以这次也采用了json文件作为配置文件。项目可移植性更高了。
这次的项目是一直这个想法,能不在主机内执行,能在docker容器打包的,都尽量在docker容器内实现,所以这次基本都是docker容器运行项目。所以容器之间的联系,也是项目的一大重点,什么在同一网络,什么不用在,还算有点复杂。
该项目第一次使用redis,但感觉不够mongodb用的舒服,因为没有嵌套关系,但也还是能解决简单问题。
本项目是AI和硬件的第一次项目,虽说硬件不是很明显,但算是一次新的尝试,虽说训练的模型确实不怎么样,但也还过的去。
缺点也很明显:训练的模型不够精确,项目还有很多能优化的地方,比如就一个tfdocker容器就2GB了。
继续努力,继续学习,继续进步!!!😂
已经搭建好的小程序: