Natapp和花生壳互补
如果这两个都用过就知道:natapp没有固定域名和端口,但没有流量限制;花生壳有固定域名和端口,但有流量限制(1G)。想一下互补一下不就完美了吗。正好之前教程已经能把natapp的域名写出来了(如果之前的config.ini文件里面配置的是loglevel=DEBUG最好改成loglevel=INFO,这个信息量少,而且这个教程也是用这个的),再有之前的php运行python的基础,所有的知识结合干好可以解决这个互补的技术问题。
这个教程思路是把natapp写出来的wwl.txt文件的信息读取出来再进行筛选出域名。然后把域名给js,先让js判断进入的网站是不是花生壳的域名,如果是就改成筛选出来的natapp的域名。所以还是挺简单的思路。
1. 筛选信息
嗯~我用的是python程序,可能js也是可以的,因为上次用的是js读取txt文件,但js毕竟不是那么熟悉,而且我也是有点c语言的基础,掌握python的应该还可以(听说python牛逼点,什么都能搞)。主要是为了懂多点东西,所以用python编程。
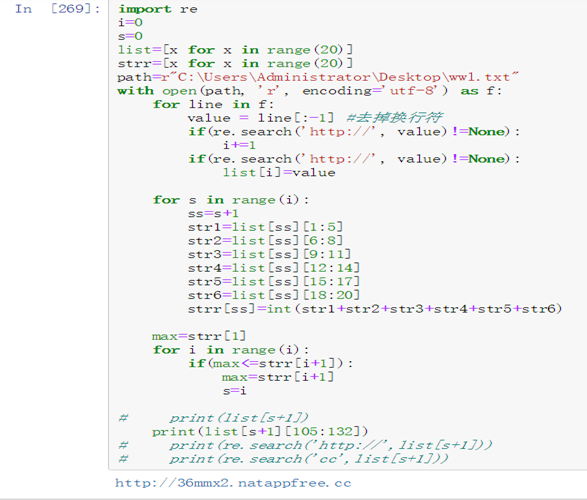 这个是真的自己写的了(再不自己写个东西你们都会觉得我是大自然的搬运工了)(因为之前做过一个大工程c语言统计学生成绩,用过类似的知识),但还是查了一点东西,因为python和c语言还是有区别的,就比如python没有i++的。这个代码也是很好理解的,主要的就几个地方:
这个是真的自己写的了(再不自己写个东西你们都会觉得我是大自然的搬运工了)(因为之前做过一个大工程c语言统计学生成绩,用过类似的知识),但还是查了一点东西,因为python和c语言还是有区别的,就比如python没有i++的。这个代码也是很好理解的,主要的就几个地方:
value = line[:-1] #去掉换行符 这个是一行一行读取文件把这个内容赋给value
re.search('http://', value) 这个的意思是检索value里面有没有http://字符串如果找到会返回字符串在value的内容的位置,没有就会返回None
那个一大串str的是为了要这里面的[2020/03/05 12:14:25 CST] [INFO] (natapp/src/log.(*PrefixLogger).Info:83) [client] Tunnel established at http://36mmx2.natappfree.cc 这个内容的2020/03/05 12:14:25,并且把这个内容的字符搞掉,为什么要这个内容,因为要靠这个时间来判断找到最新的域名,域名可能会更新所以。。。可能你们会想如果这个2020/03/05 12:14:25是字符串,直接用字符串比较大小不就行了,如果你用过c语言的strcmp函数,你就知道123<13这个了,我才不敢用这个,可能python不会有这个的,算了,就不用这个了。最后我把所有的str合成了int的数据类型存进strr里面,所以我只要判断哪个数字大就行了,其实2020可以去掉的,应该不会开一年的服务器吧。其他没有什么难懂的代码了。到了在网页上执行python,这次符合了我上次说那个东西,很难解释为什么python和python3一个可以,一个不可以。这次我还是先在系统上执行py,还是正常的,一放进网页执行,就出错了(这里我已经搞好了输出信息的配置2>&1上篇文章讲过)输出了:
TypeError: 'encoding' is an invalid keyword argument for this function(这里网上说是python2的问题,我有点知道怎么回事了)
网上查找一番后,改成如下这样就可以搞定
import io
f = io.open("xxx", "r", encoding='utf-8')
然后再次运行出现了这个:
'ascii' codec can't encode characters in position xxx: ordinal not in range(xx)
我又试很多网上的方法:
1. import sys
2. reload(sys)
3. sys.setdefaultencoding('utf8')
然后出现了:
module 'sys' has no attribute 'setdefaultencoding'
又找到了:

之后就在'ascii' codec can't encode characters in position xxx: ordinal not in range(xx)
和module 'sys' has no attribute 'setdefaultencoding'和name 'reload' is not defined
等问题之间循环,最后我只改了源程序一个io.open(path, 'r', encoding='utf-8')这个,然后把exepy.php的python3改成了python,竟然就可以了。因为我在所有出现的问题的文章里面都看到了,python2,python3什么什么那个怎么用这个代码运行,那个又用什么代码运行,所有我怀疑是不是两个又搞混了,找到这个io.open(path, 'r', encoding='utf-8')代码的标题是python 2.7版本解决TypeError: 'encoding' is an invalid keyword argument for this function 所以,我就这样只改这个,然后把exepy.php 的python3改成python。应该是这样的。
2. 传值
如果看过我之前的就知道,我是把python的输出的信息写到txt文件,然后用jquery.js读取内容并保存再cookie里面。现在搞个之前拿别
人php执行python的实例的一个方法。这个方法是可以直接把python输出的信息写的html里面的。代码:
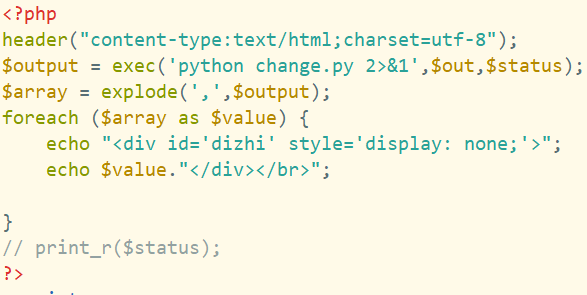
主要是这个
$array = explode(',',$output);foreach ($array as $value) { echo $value."</div></br>";}
value这个的值就是python输出的信息。
我把这个信息装进了div给个id给它,js用
var zhi = document.getElementById("dizhi");
var content = zhi.innerHTML
这个就可以把域名读取出来了,为了能从js传值出来我用了上篇(网页心得)的那个全局都能用的cookie方法(目前只会这个方法)。
3. 判断是不是花生壳地址
如果看过我上篇修改过的文章,就会发现我改了个东西,就是
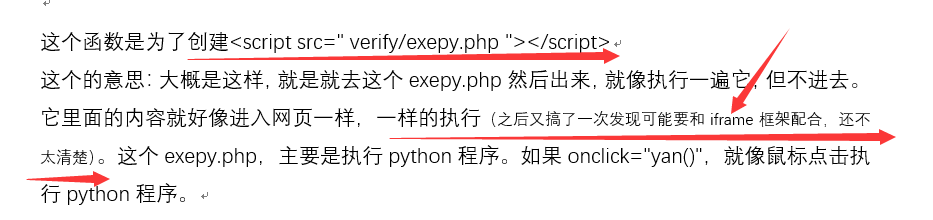
目前还没有找到真正的原因,可能是可以的不用iframe框架的,因为之前弄过了,但已经删掉那个实例了。为什么怎么会又不可以了呢?就是因为这个判断花生壳这里,出现了问题。我本来是这么个思路的:
在网页加载时就获取当前网站地址,然后判断是不是花生壳的那个域名(因为花生壳的域名是固定的) ,如果是就执行<script src=" change/exepy.php "></script> 这个,当然在js里不能这样写,但可以使用动态写入这个代码(上篇文章写到过)(其实一开始我怀疑是这个不行,才导致我以为是要iframe框架的,但没有什么思路就放弃了) ,然后没有任何反应,我看了一下目前我用这个代码是都配合了iframe框架,所以我也试了一下,可以是可以,但第一次是不会跳转,因为第一次是执行这个代码来获取域名,所以第一次载入页面时还没有域名,所以没有跳转,刷新一次就跳转了。但这个并不符合我要的效果,因为如果你域名频繁更新的话,就每次还要自己手动进入两次页面,我自己知道但用户是不知道,而且还麻烦,所以这样是不行的。然后只能这样了。就是载入页面时js判断是不是花生壳域名,是就跳转到change/exepy.php这个页面,然后这个页面的末尾就是跳转去python获取的域名。所以进入花生壳域名的页面是自动的转了两个页面,但速度够快所以用户是没有感到什么影响。但还是不是很理想,等我把<script src=" change/exepy.php "></script> 这个研究清楚先,就可以避免这种情况了。
到目前已经完成了花生壳和natapp的互补了。